• License Plate Recognition (2019)
Project: To perform license plate recognition, on the edge (very low power in-camera chipset), cloud, or combination of the edge and cloud.
We built tiny neural networks to achieve this task. These are End-to-End mixed-precision quantized YOLO-like models that are extremely fast, yet
very accurate. These models run on different platforms from GPU servers all the way to Nvidia JetSonTX2, Google Coral, PaspberryPi 3+, and in-
camera 3516EV300 chipsets.
Demo:
• Hand Gesture Recognition (2018)
Project: By 2018, there are already many successful models proposed for gesture recognition. This project investigated the practicallity of those
models for real-time applications. To this end, we leveraged a custom TRN (Temporal Relations Network) structure to train a model over the Jester
dataset for hand gesture recognition. This model could classify one of several designed actions in under 50 ms. Later the model outputs were
translated to a humanoid robot directions for a live demonstration:
Demo:
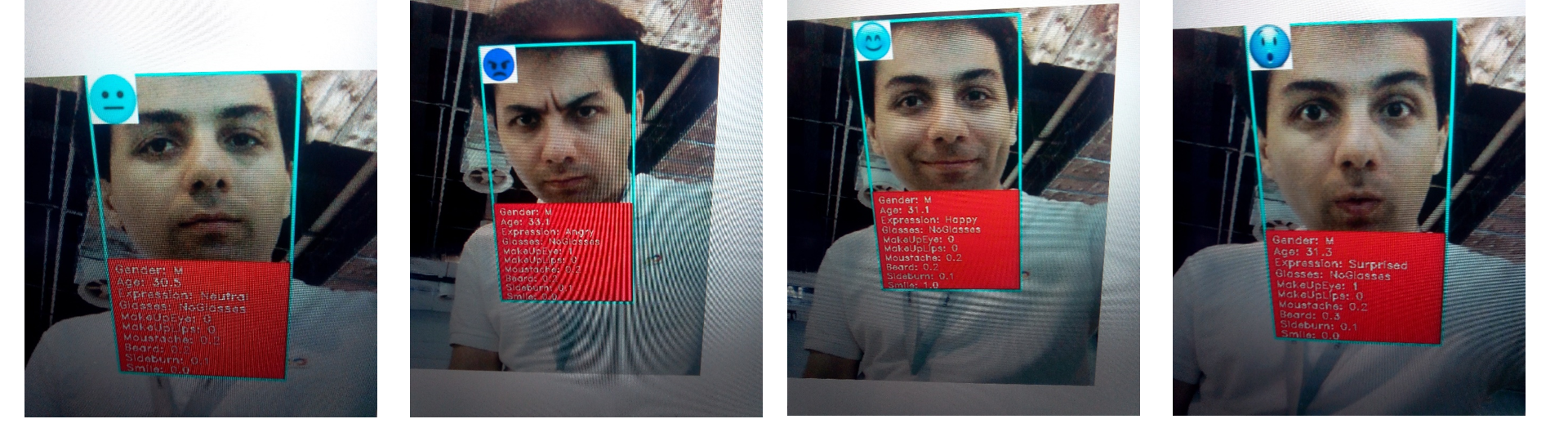
• Facial Attributes Recognition (2018)
Project: Facial attributes recognition for deployment on low power chips. We designed and trained a multi-task neural network with over 10
branches to recognize attributes such as age, gender, smile, makeup, facial hair, eye-glasses, etc. This model runs on JetSonTX2 under 100 ms per
frame.
Demo:
• Face Detection and Recognition (2018)
Project: To perform face detection and recognition for various applications (various speed, accuracy, and dataset size requirements; clustering,
classification, or id recognition). This involved with exploring/modifying various deep learning frameworks/models, to train/transfer-learn for
detection and recognition tasks.
Demo:
For this demo, I used the PubFig dataset (Public Figures Face Dataset) as face id candidates, LFW datset (Labeled Faces in the Wild) for training,
and tried a couple of YouTube videos for fun (watch full screen in high resolution setting to read the labels!):
• Text Detection and Recognition (2018)
Project: Detect and recognize (read) text from video/image. This involved with exploring the state-of-the-art OCR (Optical Character Recognition)
models. Various Attention-based CNN/RNN models were used for detection, recognition, or end-to-end tasks. Traditional OCR approaches fail for a
non-flat warped background with transformations.
Demo:
Using a separate detection and character level recognition framework, I trained deep learning based models, and applied them to a couple of
YouTube vidoes below. In each video, bounding boxes are first detected around the text area, then text crops are shown below the actual video
frame (sorted according to recognition confidence). For each text crop (bounding box), the title above shows what the recognition model has found.
Although the detection seems to have high precision and high recall, I believe recognition can still be further improved.
• Command Recommendation in an IDE environment (2017)
Project: Modern Integrated Development Environments (IDEs) often provide next command recommendation to the users to ease the development
process. A current approach is to use co-occurrence analysis, that has a superior performance compared to the traditional supervised learning
approaches. In this project we explored the usage of deep neural networks for this task. We trained a custom LSTM network and demonstrated it
can perform on-par with the co-occurrence method.



Amin Banitalebi Dehkordi, PhD
(Amin Banitalebi)
(Amin Banitalebi)
Links
Copyright © 2022 by "Amin Banitalebi" · All Rights reserved · E-Mail: amin[dot]banitalebi[at]gmail.com






PUBLICATIONS: click here
DATASETS: click here
ACADEMIC PROJECTS: click here
Visit my Google Scholar page here.
Projects

• Detecting and Analyzing Objects in a Conveyor Belt Surveillance Video:
Project: To understand and analyze the objects moving on a conveyor belt, in a dim environment
Solution: Using connected component segment analysis and contour detection to find objects
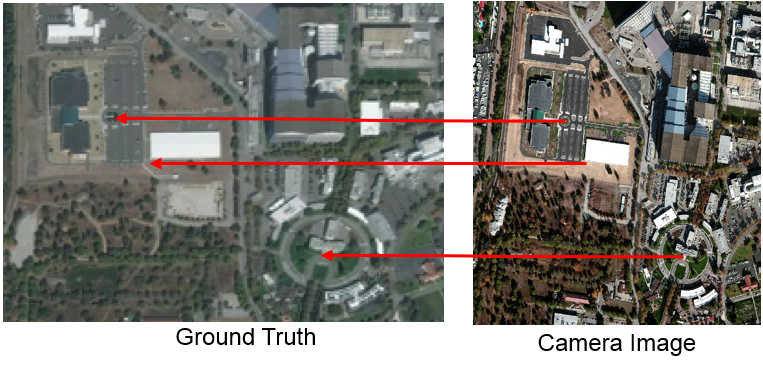
• Ultra-Accurate Image Registration:
Project: Register an image aquired by a camera on board of a satellite to a ground-truth image on the ground, accurate to half-a-pixel
Solution: A complex mathematical optimization approach based on extended Kalman filtering. The optimization is very flexible, accounts for
uncertainty in the measurements and independent variables, converges in only a few iterations in less than 10-30 seconds.
Before Registration:
Matching:
After Registration:
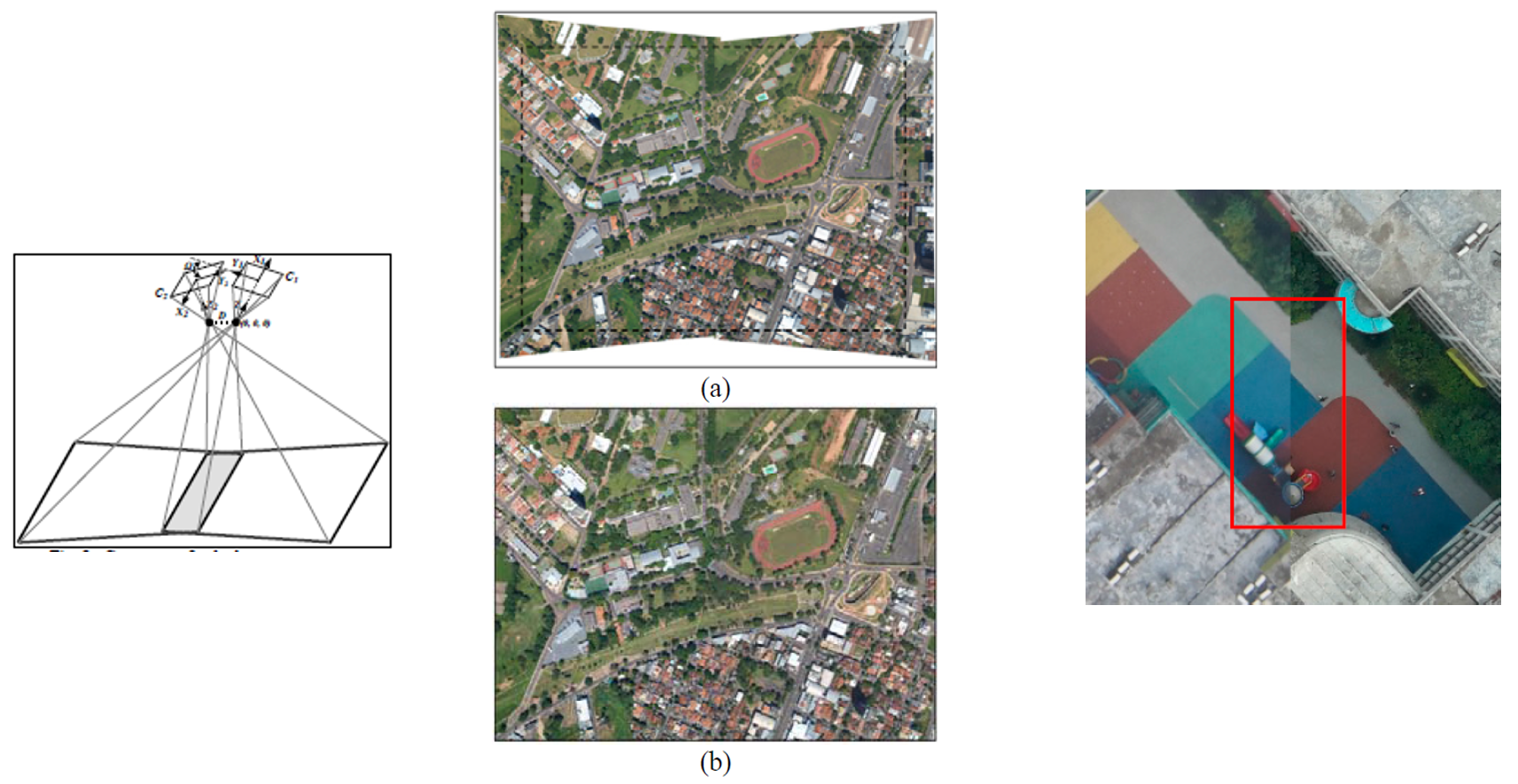
• Ultra-Accurate Registration of Multiple Images - Bundle Adjustment:
Project: Register multiple images obtained from different satellite cameras together, and to a ground truth image on the ground
Solution: Optimization using extended Kalman filters. The overlapping area between multiple images has a half-a-pixel registration accuracy. This
accuracy is better than the accuracy obtained by registering every image against the ground truth reference image. The figure below shows slight
misregistration remaining in an overlapping AOI.
• Video Frame Stabilization:
Project: Register a stack of video frames from a satellite camera to each other, and to a ground truth reference image
Solution: Optimization using extended Kalman filters to register each frame first. This will produce a video, with a remaining degree of
misregistration. Then, register every frame against the median of center frames. The resulting video will have a sub-pixel frame-to-frame
regostration.
Original video, before registration:
After the initial optimization (AOI):
Final video (AOI):




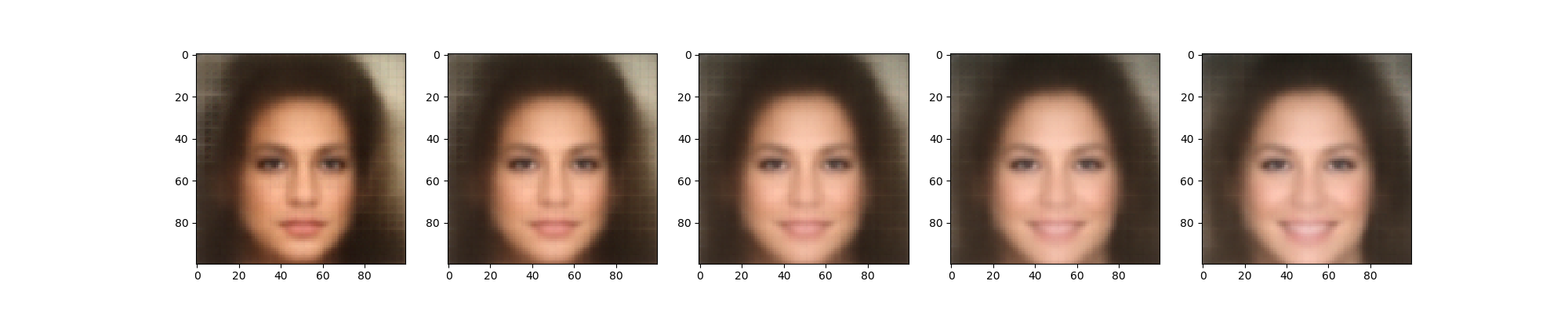
• Style Transfer with Variational Generative Adversarial Network (GAN):
Project: To demonstrate latent space arithmetics when using Variational GANs
Demo:
Using CelebFaces dataset, to demonstrate Male-to-Female transfer:
No-Smile to Smile transfer:
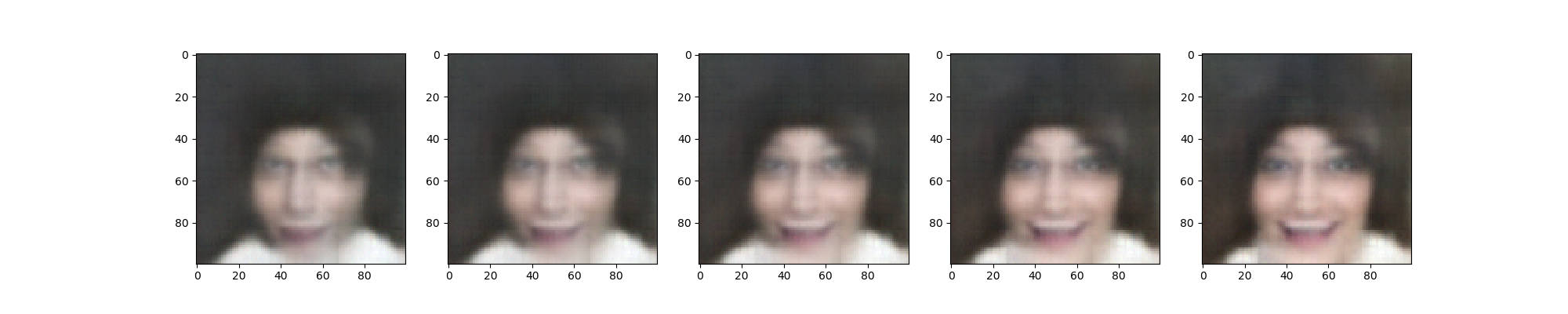
I tried my childhood picture (with no alignment) to Smile transfer. Looks like it needs alignment, but shows the concept:


• Ortho Rectification:
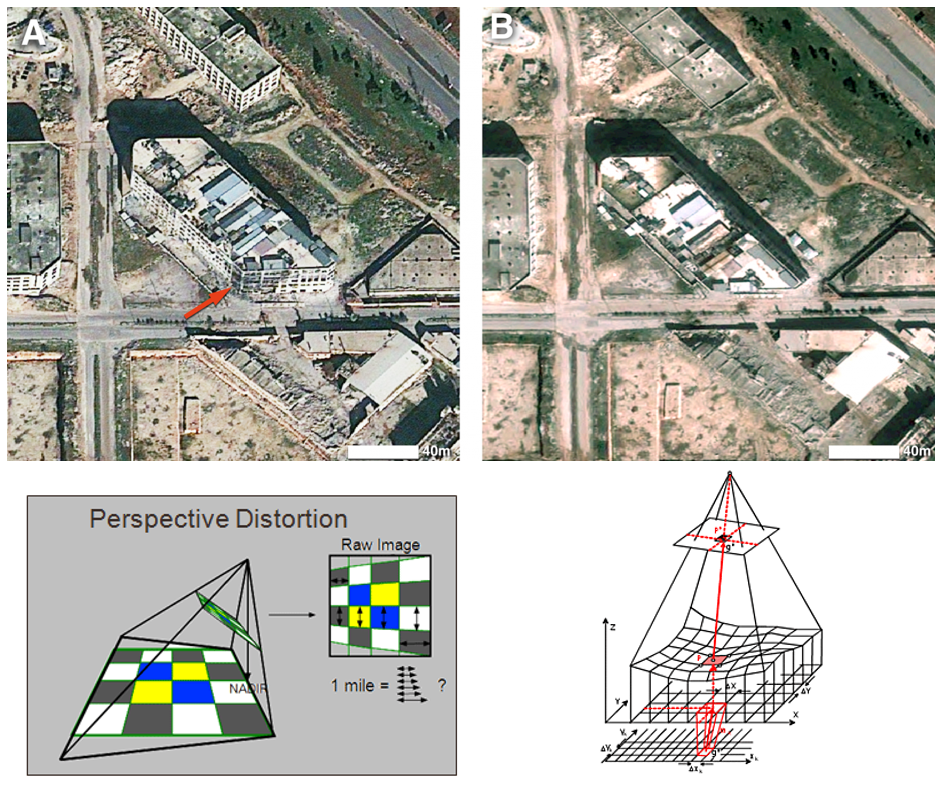
Project: To project images acquired by a sensor, to the ground plane. Involves with efficient resampling algorithms.
Demo:
• 2D to 3D Video Conversion:
Project: To automatically convert 2D video to 3D
Solution 1: To train a learning model that can generate depth maps from 2D video. And then use depth maps to generate additional views.
Solution 2: To estimate a depth map in an optimization problem, then perform motion segmentation to assign a depth value to each object. This
was followed by depth map post filtering for quality enhancement and flicker reduction.


• Other Projects Worth a Mention:
- Image/Video enhancement and restoration (parallel implementation using Amazon AWS EMR):
- Lightness contrast stretching
- Adaptive histogram equalization
- Saturation, color temperature adjustment, gamma correction, sharpenning
- Tone-mapping and color space conversions
- Frame-rate up/down conversion:
- Filling bad or no-data pixels
- Python implementation with C++ SWIG bindings for efficient interpolation/extrapolation
- Patch-matching to restore corrupted sections of video frames
- Compiling a huge MATLAB code base using MATLAB Compiler
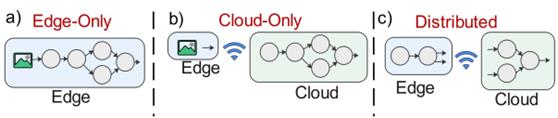
• Distributed Inference / Edge-Cloud Collaboration:
- Joint bit-width assignment and neural network splitting for distributing the inference between an edge and cloud or more
- Integrated as a pipeline to HiLens (a Huawei edge device and platform)
- Implemented for a license plate recognition application (3516 arm chip)

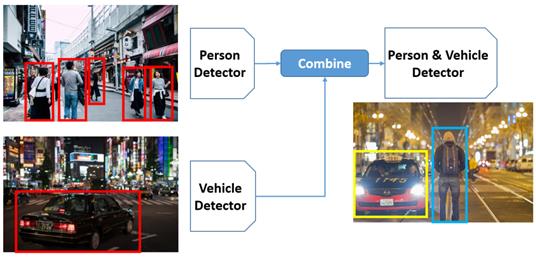
• Model Composition:
- Combine multiple models in one, without labeled data of all tasks (tasks could be partially overlapping or non-overlapping)
(Download: BMVC Paper Code)
• Robust Object Detection / Domain Adaptation:
- Make object detection models robust to domain shifts such as image corruptions, weather/lighting changes, etc.
- Support domain changes such as natural image to cartoon, painting, clipart
- Train on one dataset and test on another
(Download: ICCV Paper Code)
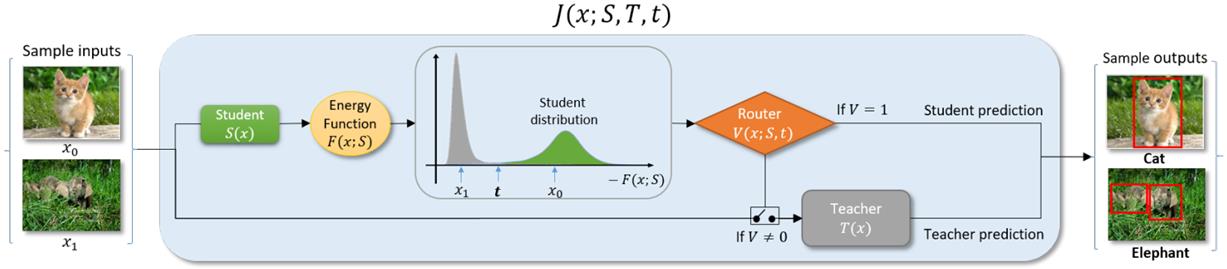
• Joint Inference:
- Use a large & small model together to distribute inference based on the inputs characteristics
- Goal: Preserve the accuracy, but speed-up the inference
- Unsupervised & specialized extensions
- Applied to Vision (Image Classifiaction, Object Detection, ...) and NLP (Classification, Translation on BERT, T5, ...)
(Download: BMVC Paper Code)